|
Xin Wen / 温鑫 I obtained my PhD at HKU under the supervision of Prof. Xiaojuan Qi. Previously, I obtained my Bachelor's degree from Tongji University. I also spent some time at Meta FAIR. I work on pre-training and capabilities of multimodal foundation models. Email / Github / Google Scholar / LinkedIn / X |

|
|
|
*equal contribution, †project lead |
|
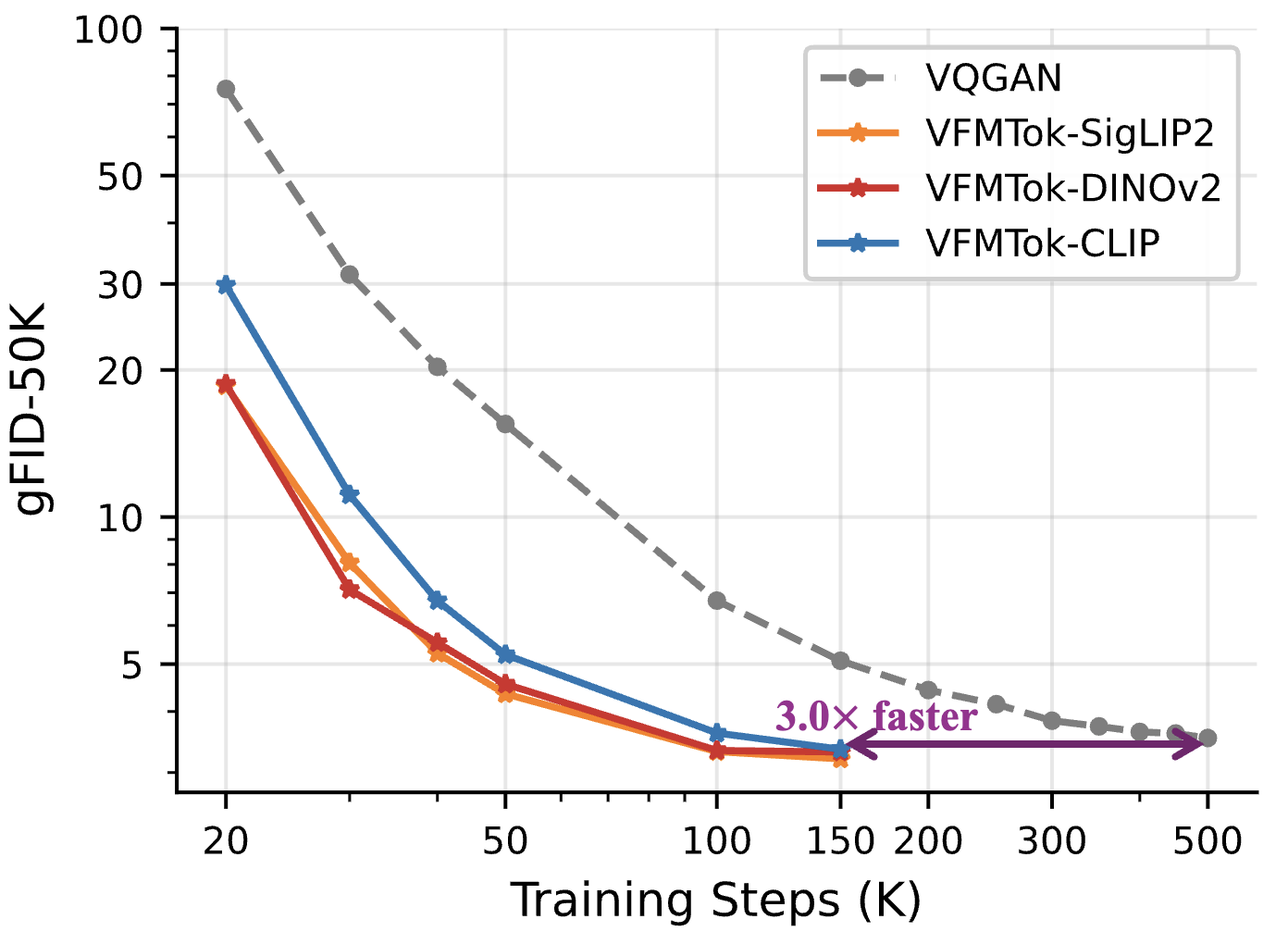
Anlin Zheng, Xin Wen, Xuanyang Zhang, Chuofan Ma, Tiancai Wang, Gang Yu, Xiangyu Zhang, Xiaojuan Qi Advances in Neural Information Processing Systems (NeurIPS), 2025 ArXiv / Code We show how vision foundation models (DINOv2/SigLIP2) can be transformed into powerful visual tokenizers for autoregressive image generation. |

|
Xin Wen*, Bingchen Zhao*, Ismail Elezi, Jiankang Deng, Xiaojuan Qi IEEE International Conference on Computer Vision (ICCV), 2025 Project Page / ArXiv / Code / Poster We introduce a novel framework that embeds a provable PCA-like structure into the latent token space, enabling 1D coarse-to-fine visual tokenization. |

|
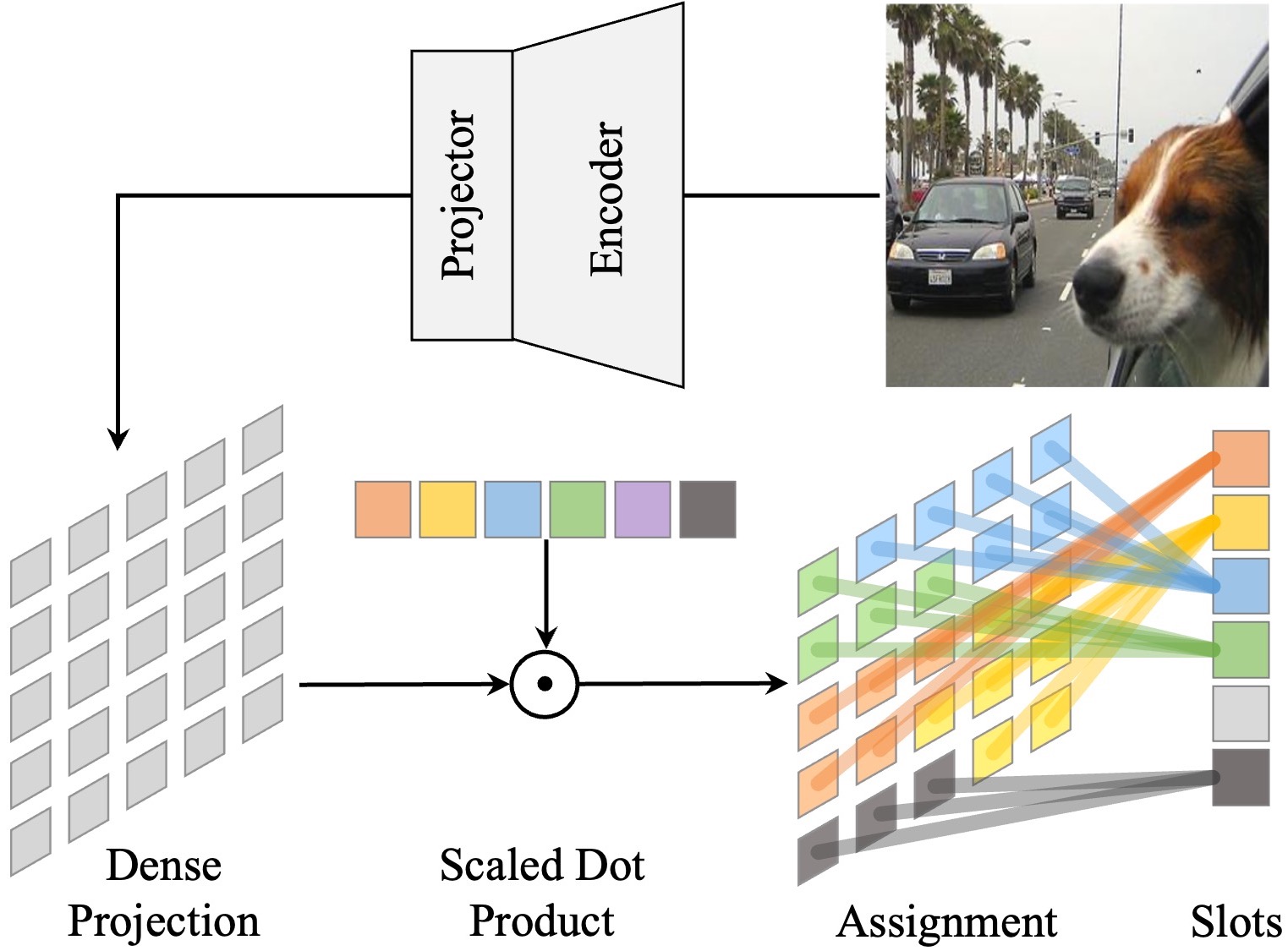
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, Xiaojuan Qi IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 ArXiv / Code / Poster We designed SlotMIM, a method that induces object-centric representations from non-object-centric images, which we find facilitates robot learning. |
|
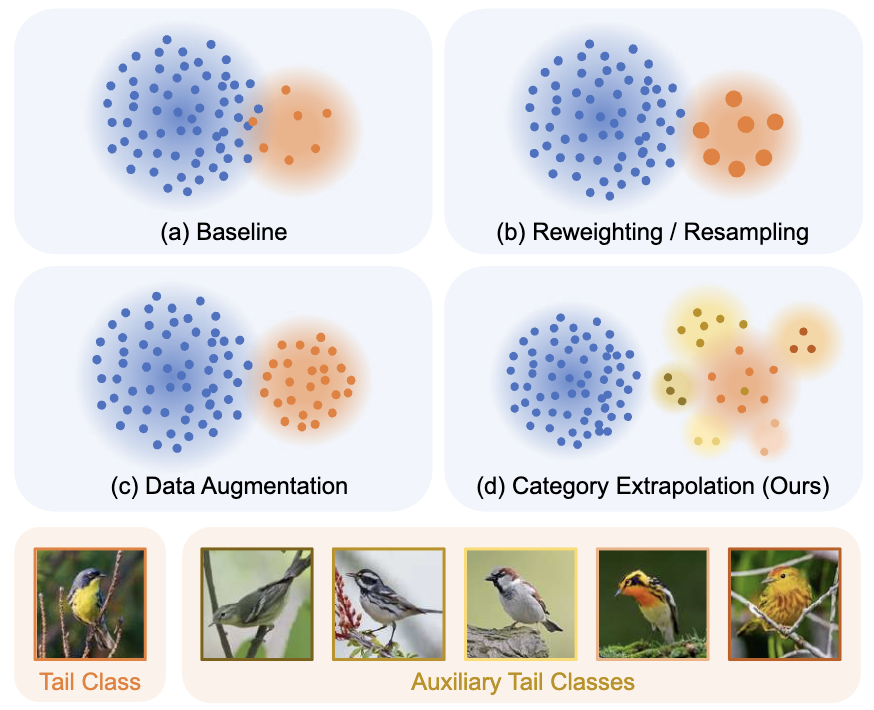
Shizhen Zhao, Xin Wen, Jiahui Liu, Chuofan Ma, Chunfeng Yuan, Xiaojuan Qi IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 ArXiv We find extrapolating tail classes with novel classes that share similar semantics with tail classes significantly improves long-tail recognition. |
|
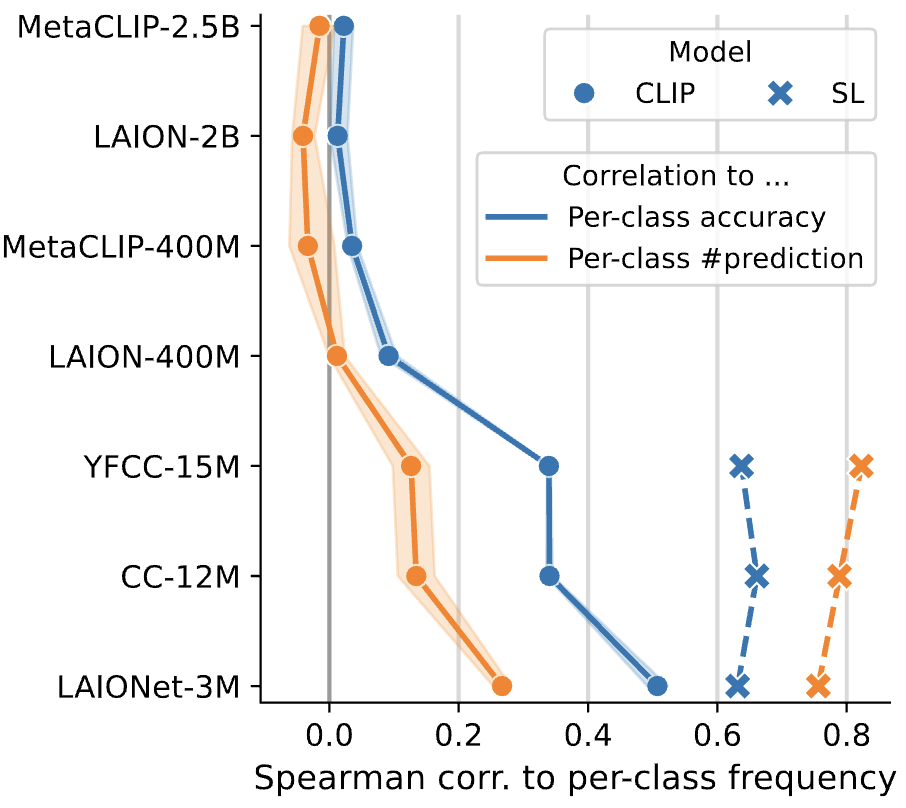
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, Xiaojuan Qi Advances in Neural Information Processing Systems (NeurIPS), 2024 ArXiv / Code / Slides / Poster We find CLIP to be relatively robust to pre-training data imbalance, design and conduct controlled experiments to identify the underlying mechanisms and provide insights for open-world recognition and SSL models. |

|
Jiahui Liu, Xin Wen, Shizhen Zhao, Yingxian Chen, Xiaojuan Qi European Conference on Computer Vision (ECCV), 2024 ArXiv / Code We introduce an automatic data curation process that leverages foundation models as tools to harvest meaningful data from text-to-image generation models for OOD object detection. |
|
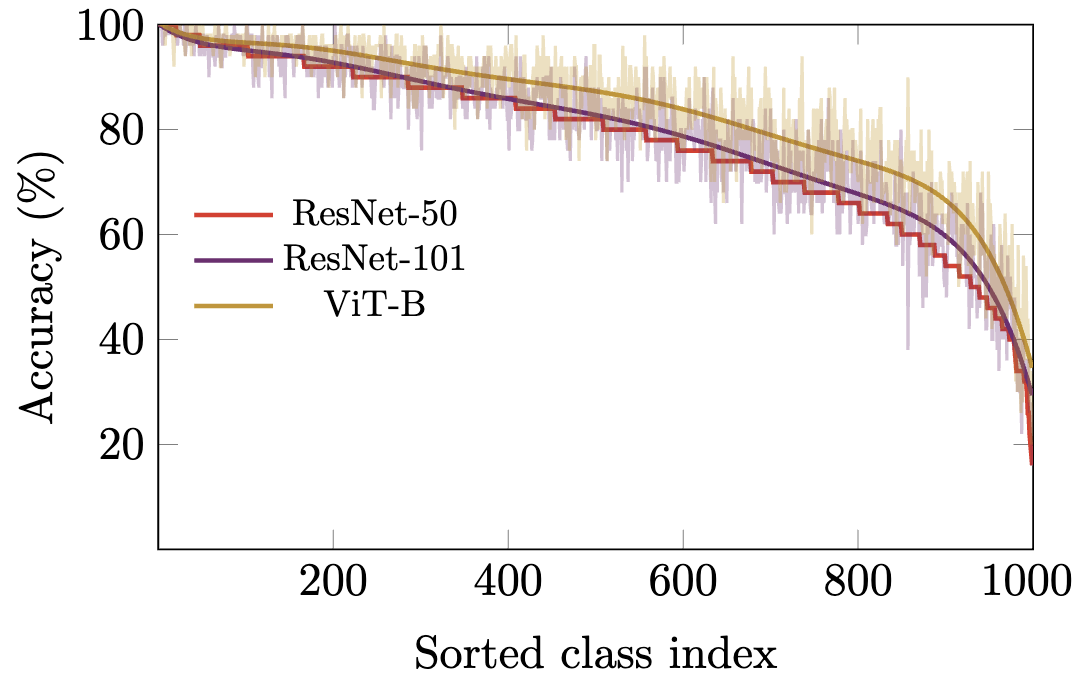
Jiequan Cui, Beier Zhu, Xin Wen, Xiaojuan Qi, Bei Yu, Hanwang Zhang IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 ArXiv / Code We show that models can still have extremely biased behaviors when trained on balanced ImageNet, investigate the reasons behind, and provide some workarounds. |
|
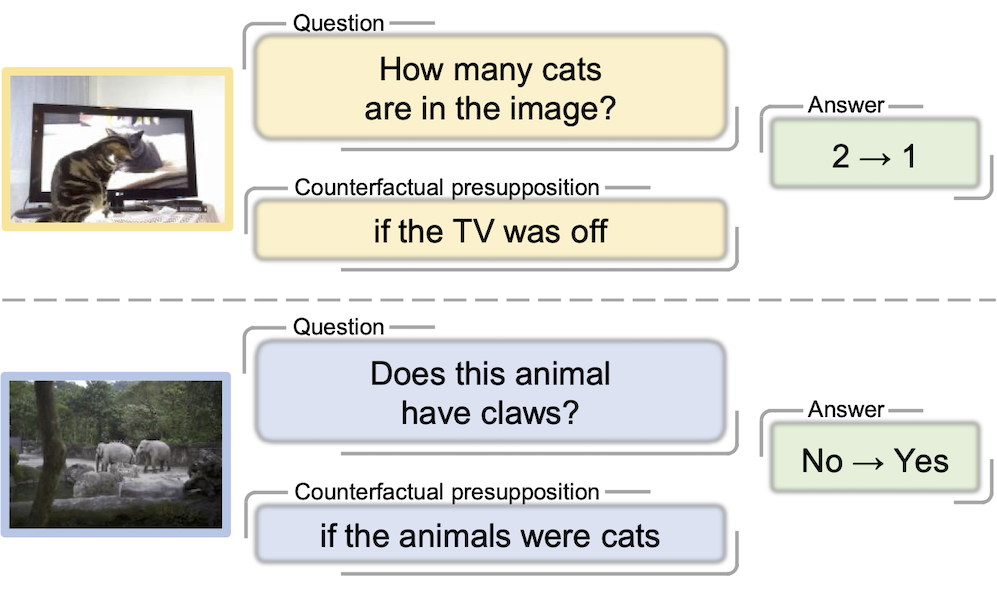
Letian Zhang, Xiaotong Zhai, Zhongkai Zhao, Yongshuo Zong, Xin Wen†, Bingchen Zhao† IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 Project Page / ArXiv / Code We build a counterfactual visual question answering benchmark, and show that strong VLMs, even GPT-4, cannot handle them very well. |
|
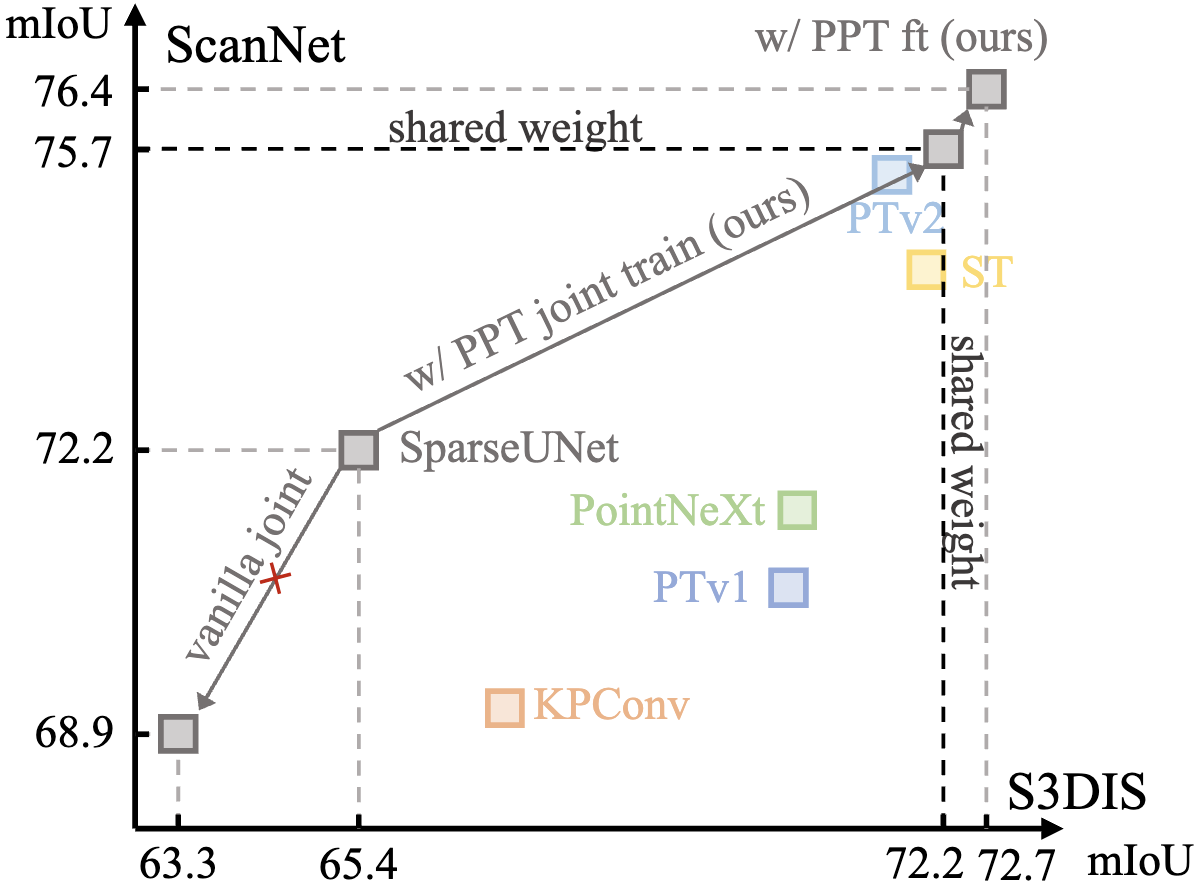
Xiaoyang Wu, Zhuotao Tian, Xin Wen, Bohao Peng, Xihui Liu, Kaicheng Yu, Hengshuang Zhao IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024 ArXiv / Code We investigate the techniques to enable 3D representation learning at unprecedented data scale. |
|
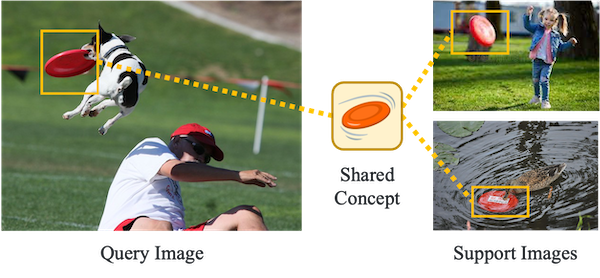
Chuofan Ma, Yi Jiang*, Xin Wen*, Zehuan Yuan, Xiaojuan Qi Advances in Neural Information Processing Systems (NeurIPS), 2023 Project Page / ArXiv / Code We bridge the gap between vision & language spaces by reformulating region-word alignment as co-occurring object discovery, and images that mention a shared concept in their captions are grouped together. |
|
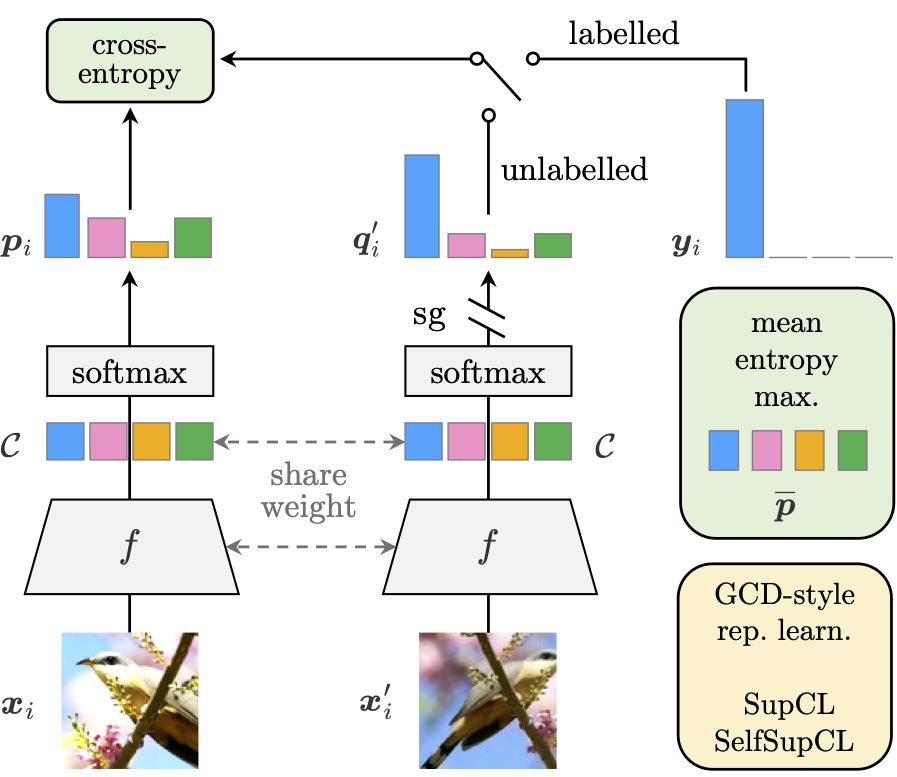
Xin Wen*, Bingchen Zhao*, Xiaojuan Qi IEEE International Conference on Computer Vision (ICCV), 2023 Project Page / ArXiv / Code / Slides / Poster We revisit why previous parametric classifiers fail to recognise new classes for GCD, and propose a simple SoTA framework. |
|
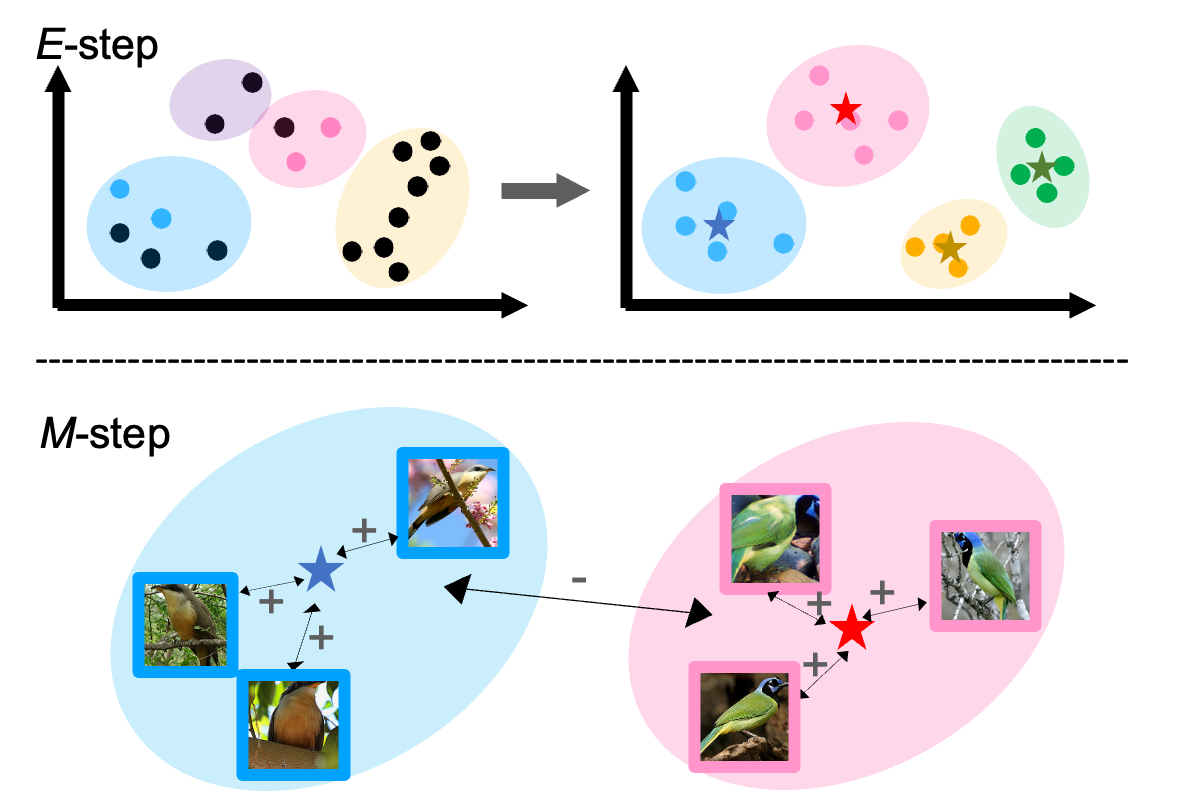
Bingchen Zhao, Xin Wen, Kai Han IEEE International Conference on Computer Vision (ICCV), 2023 ArXiv / Code We tackle GCD without knowing the class number as a-priori, propose a semi-supervised variant of GMM with stochastic splitting and merging to dynamically determine prototypes, and leverage prototpyical contrastive learning for representation learning on partially labelled data. |
|
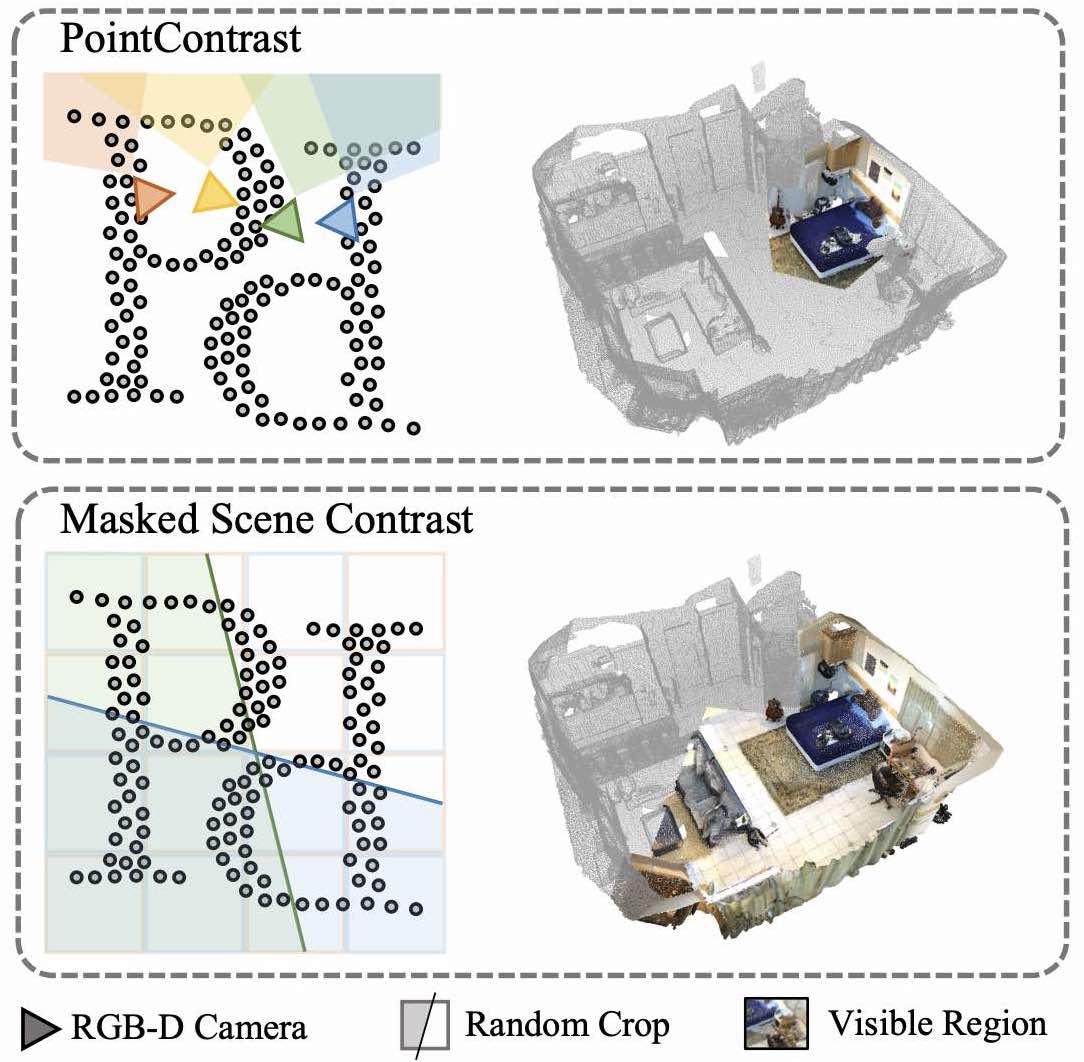
Xiaoyang Wu, Xin Wen, Xihui Liu, Hengshuang Zhao IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023 ArXiv / Code We propose the Masked Scene Contrast (MSC) framework for unsupervised 3D representation learning, which efficiently generates contrastive views directly on scene-level point clouds and enables large-scale 3D pre-training across multiple datasets. |
|
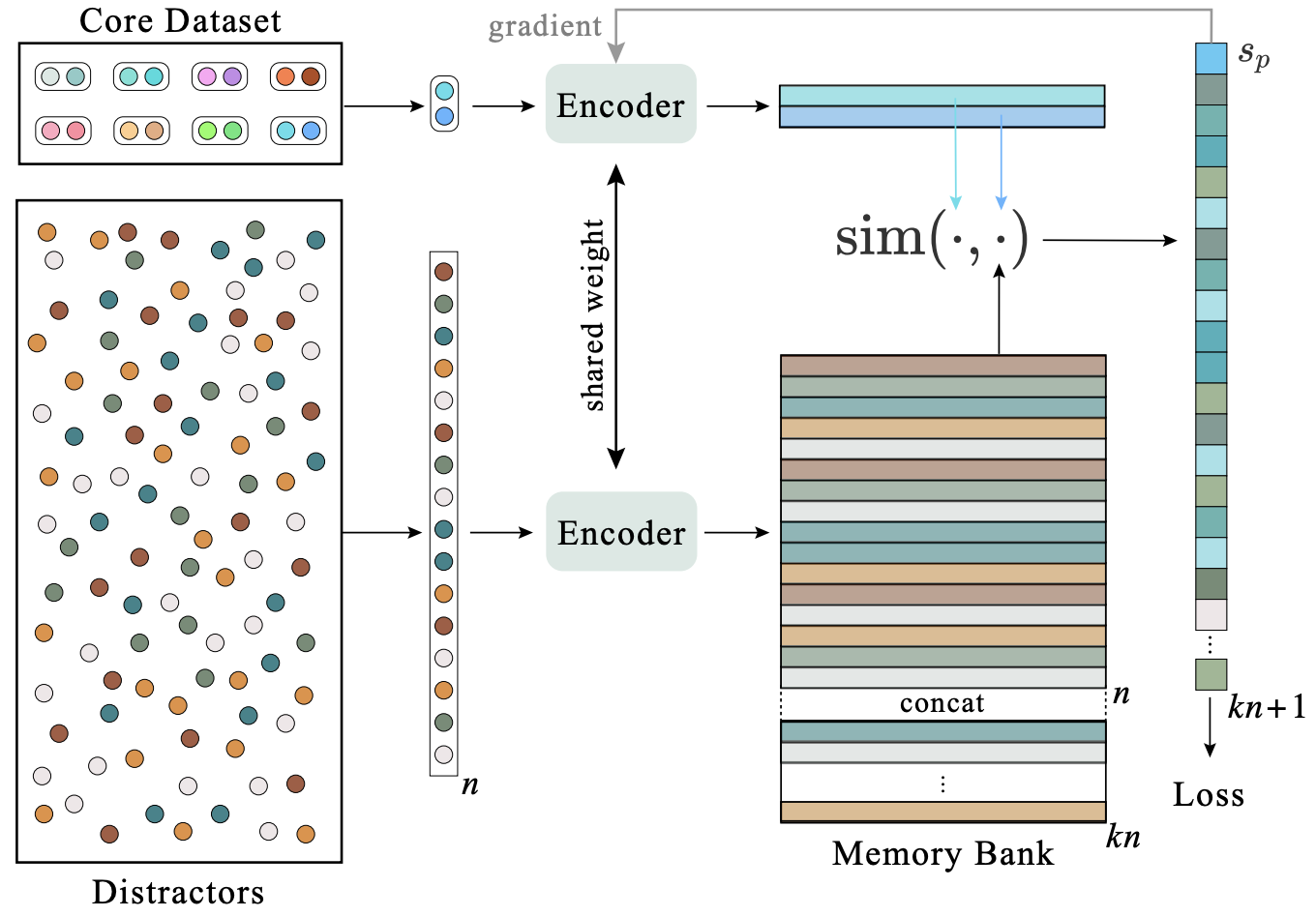
Xin Wen, Bingchen Zhao, Anlin Zheng, Xiangyu Zhang, Xiaojuan Qi Advances in Neural Information Processing Systems (NeurIPS), 2022 Project Page / ArXiv / Code / Slides / Poster We show that object discovery can be learned jointly with the representations from scratch on real-world scene-centric data, which leads to strong transfer learning results in various downstream tasks. |
|
Jie Shao*, Xin Wen*, Bingchen Zhao, Xiangyang Xue IEEE Winter Conference on Applications of Computer Vision (WACV), 2021 ArXiv / Code / Slides We present a video representation learning framework that adopts long-range temporal information between frame-level features using self-attention. |
|
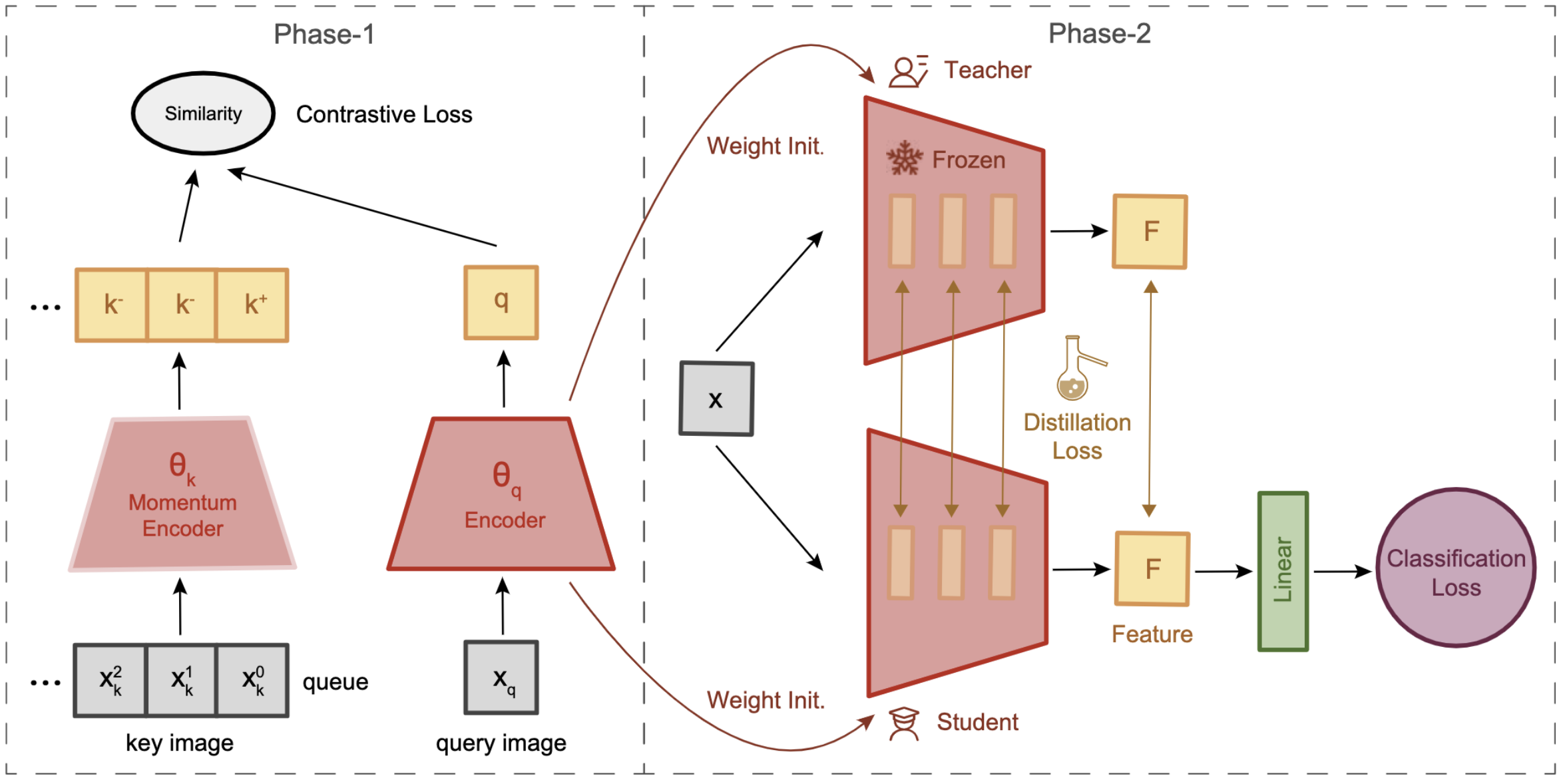
Bingchen Zhao, Xin Wen European Conference on Computer Vision (ECCV) VIPriors Workshop, 2020 ArXiv / Code / Slides We leverage self-supervised learning and knowledge distillation to improve the generalizability of CNN models for image classification under the data-deficient setting. |
|
|
Reviewer for TPAMI, IJCV, NeurIPS, ICLR, ICML, CVPR, ICCV, ECCV, WACV, CVinW, OOD-CV, and AI4VA. |
|
Template gratefully stolen from here. |